See It in Action
Explore the intuitive interface designed for professional video generation workflows
Generation Space
The main workspace for configuring and launching video generation tasks with real-time previews and progress tracking.
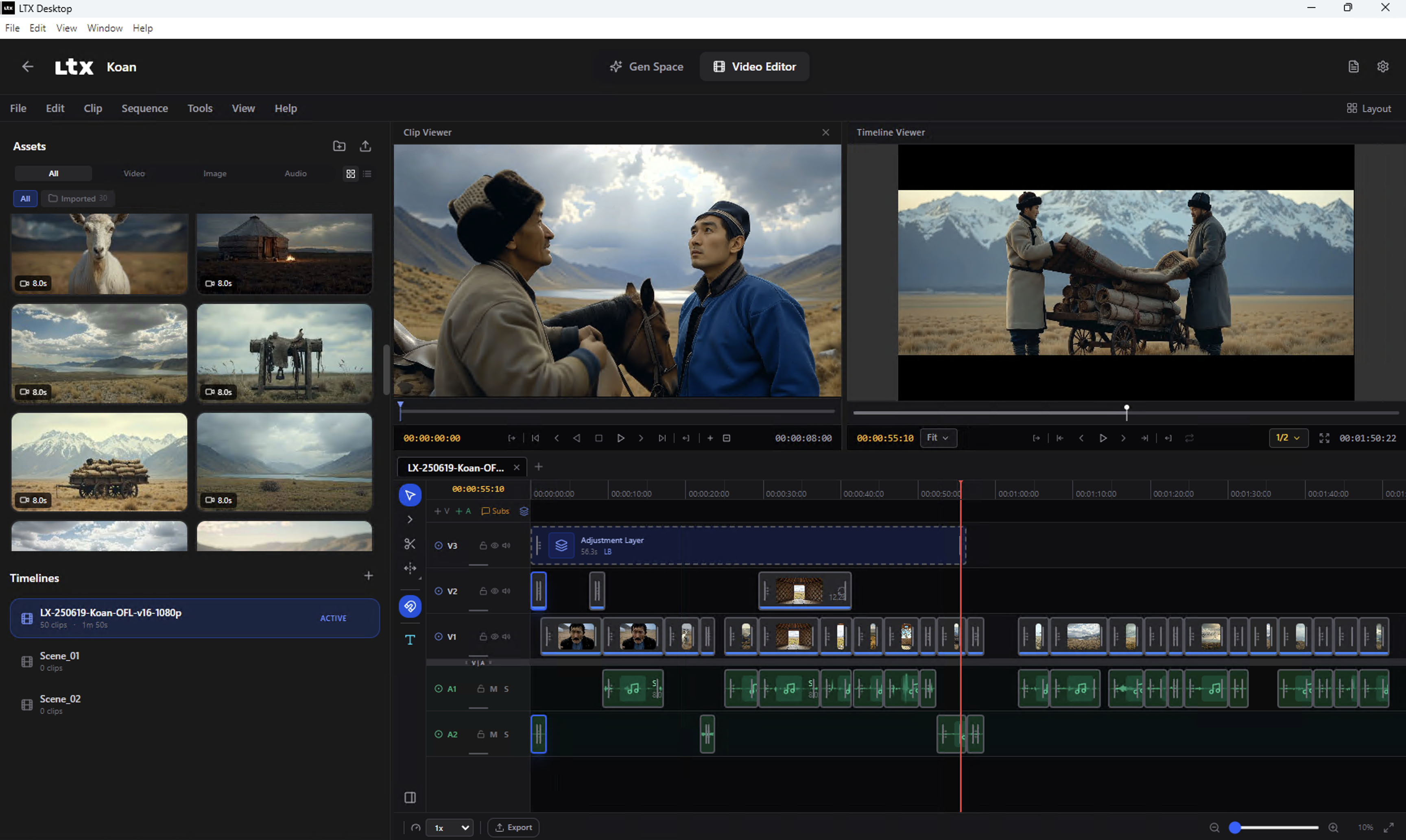
Video Editor
Professional timeline editor with drag-and-drop functionality, clip management, and precise editing controls.
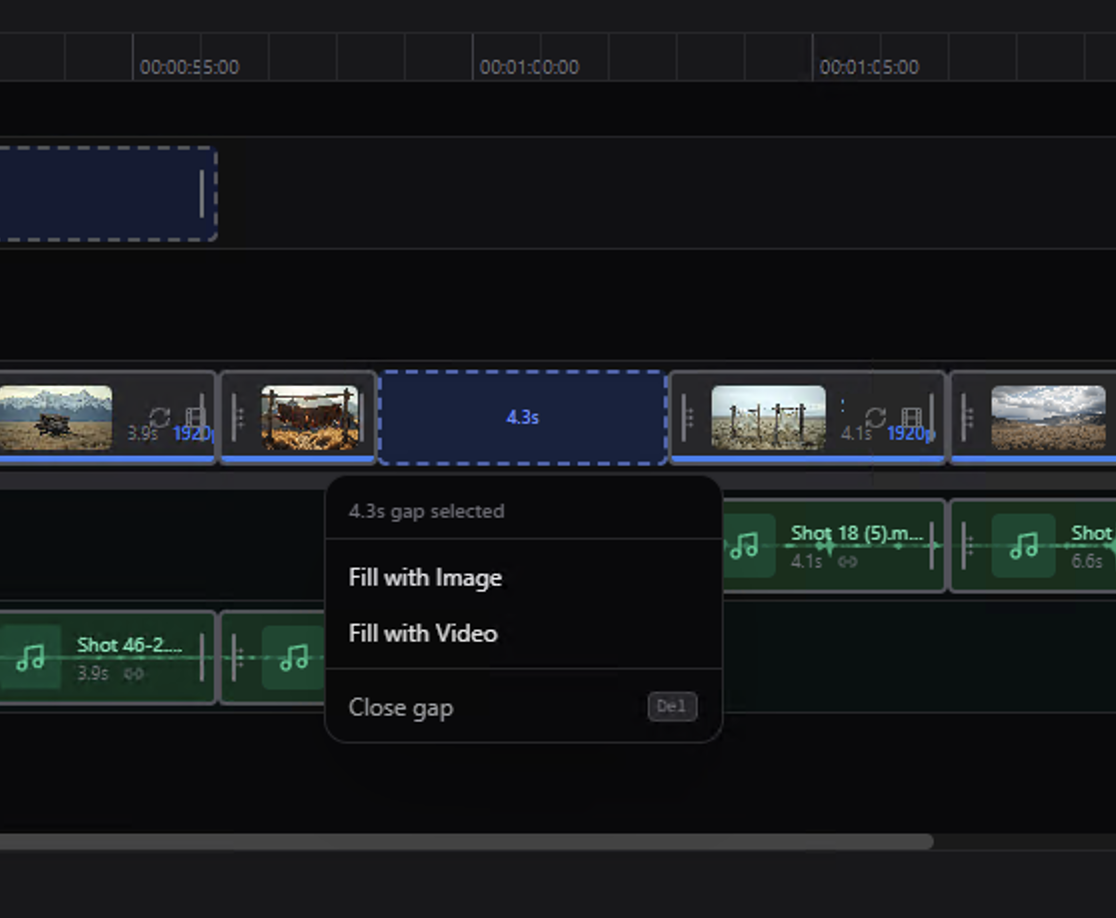
Timeline Gap Fill
Intelligent gap detection and AI-powered filling to seamlessly complete video sequences and transitions.